
")
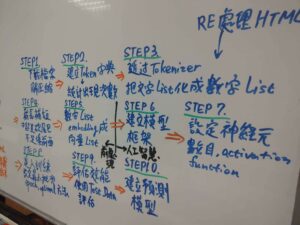
這張醜醜的白板圖是常用 NLP自然語言 解析應用步驟,我上課的時候說明的。
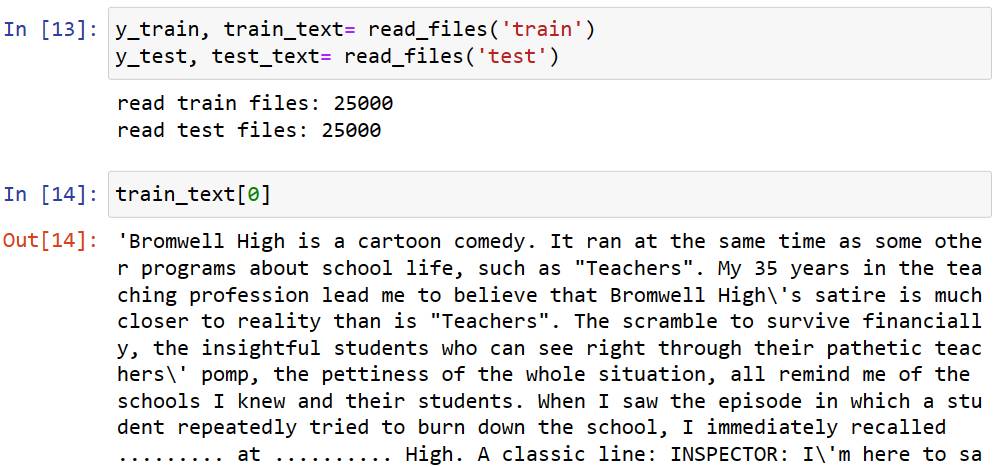
這個應用例是IMDB的影評分析,使用的是IMDb(Internet Movie Database)線上電影資料庫,始於 1990 年,1998 年起,成為amazon旗下的網站,收錄了4百多萬筆作品資料。IMDb 資料集共有 50000 筆影評文字,分訓練與測試資料各 25000筆,每一筆資料都被標記為「正面評價」或「負面評價」。新版的IMDb資料集做了更多的分類,總共有七種,有興趣的可以參考 https://www.imdb.com/interfaces,我們這邊用舊版的來說明。
大綱
STEP1.下載檔案、解壓縮
STEP2.建立Token字典、統計出現次數
STEP3.透過Tokenizer,把文字化成數字List
STEP4.截長補短。超過砍尾巴、不足填前面
STEP5.把數字List embedding成向量List
STEP6.建立模型框架
STEP7.設定神經元數目、激發函數(activation function)類型
STEP8.進入訓練,設定最小批次、epoch及optimal方法
STEP9.評估效能,使用Test Dataset評估
STEP10.建立預測模型
結語
STEP1.下載檔案、解壓縮
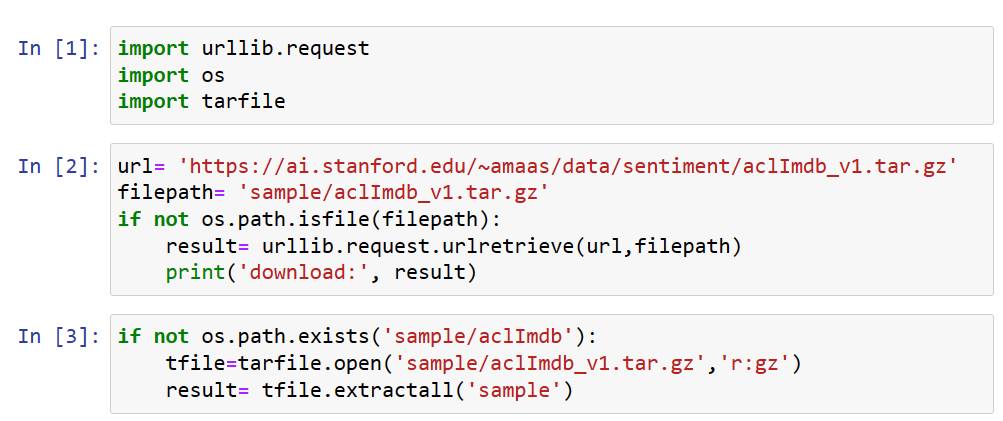 將檔案從史丹佛大學下載,檢查是否已經存在,若不存在則建立並解壓縮。
將檔案從史丹佛大學下載,檢查是否已經存在,若不存在則建立並解壓縮。
STEP2.建立Token字典、統計出現次數
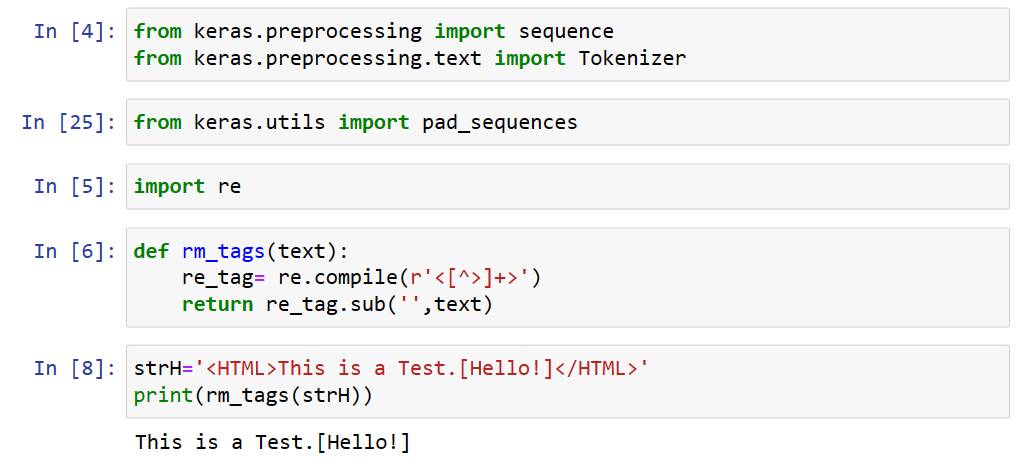
導入用到的Packages,先進行正規化表示法(RE, Regular Expression)的設定,用來去除標籤。因為有些資料檔裡面還留有標籤文字的符號,RE去除標籤的詠唱語法為<[^>]+>,一不小心還以為是表情符號呢。
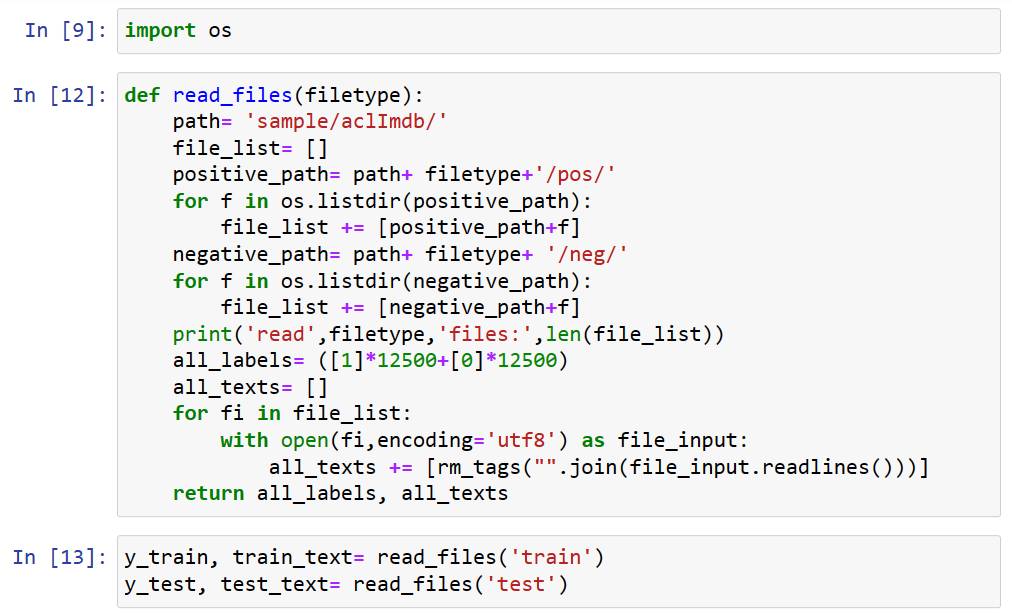
把資料集的資料進行分配,資料夾名稱為train的設定為訓練資料集,test的設定為測試資料集。
檢查一下筆數內容有沒有問題。
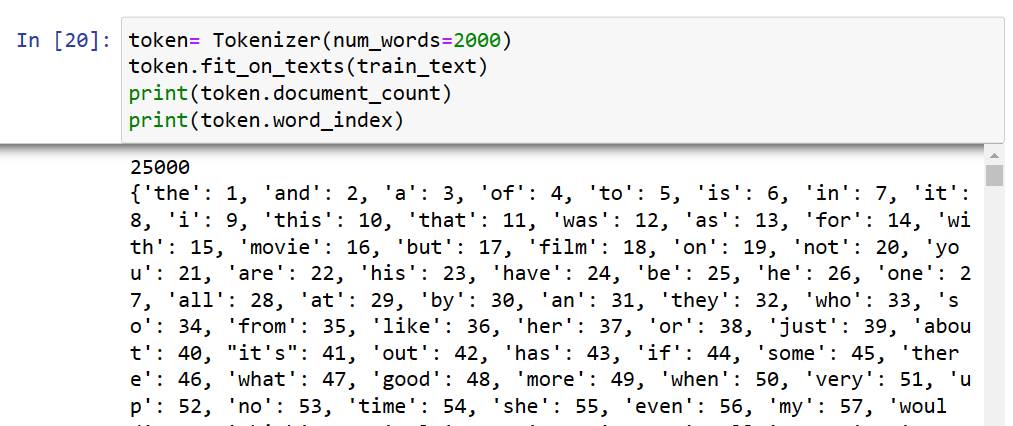
建立Token字典,數字的順序是文字出現的次數累計,最多的排第一。
STEP3.透過Tokenizer,把文字化成數字List
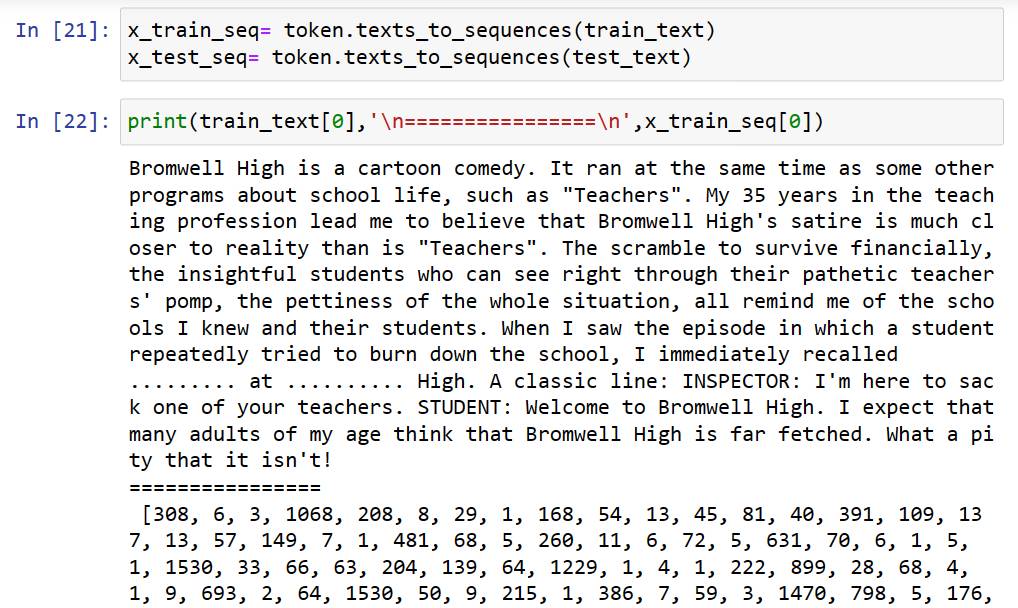
把文字化成數字List,並檢查一下有沒有問題。
STEP4.截長補短。超過砍尾巴、不足填前面

截長補短,這篇比較長就被刪掉了。資料格式也從原來的list轉換為ndarray的數字矩陣型態。
STEP5.把數字List embedding成向量List
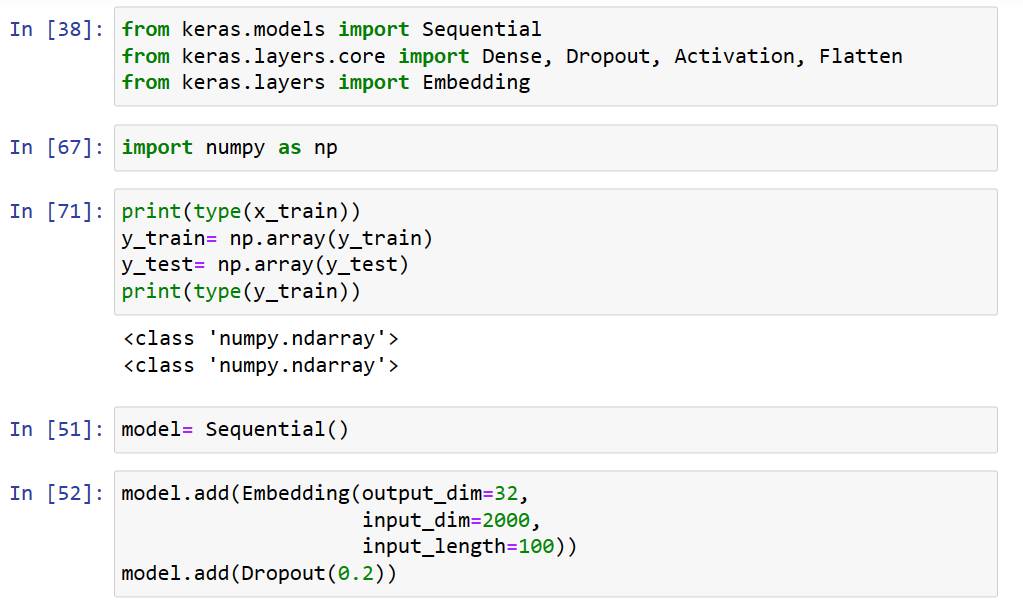
載入Packages, 把正負評價輸出從list轉換為ndarray型態,以利後續訓練。並建立Embedding層,把輸入的內容轉換為32個向量型態。並增加20%的Dropout。
STEP6.建立模型框架

前一個STEP的這一行就是建立線性模型框架。Embedding跟Dropout都是屬於線性模型框架中的操作。
STEP7.設定神經元數目、激發函數(activation function)類型


- 建立平坦層。
- 新增一層神經元為256的隱藏層,激發函數為relu。
- 建立一層捨棄率為35%的Dropout層。
- 建立一層神經元為1的輸出層,因為只有正評跟負評,用一個神經元就夠了,1為正評,0為負評。激發函數為sigmoid,這裡也可以用softmax作為激發函數。
- 看一下模型的摘要,這次用了88萬個參數,算是少的了。
在中間如果寫錯的話,修改完後記得從Sequential()開始跑喔,不然模型會累積下去。
STEP8.進入訓練,設定最小批次、epoch及optimal方法
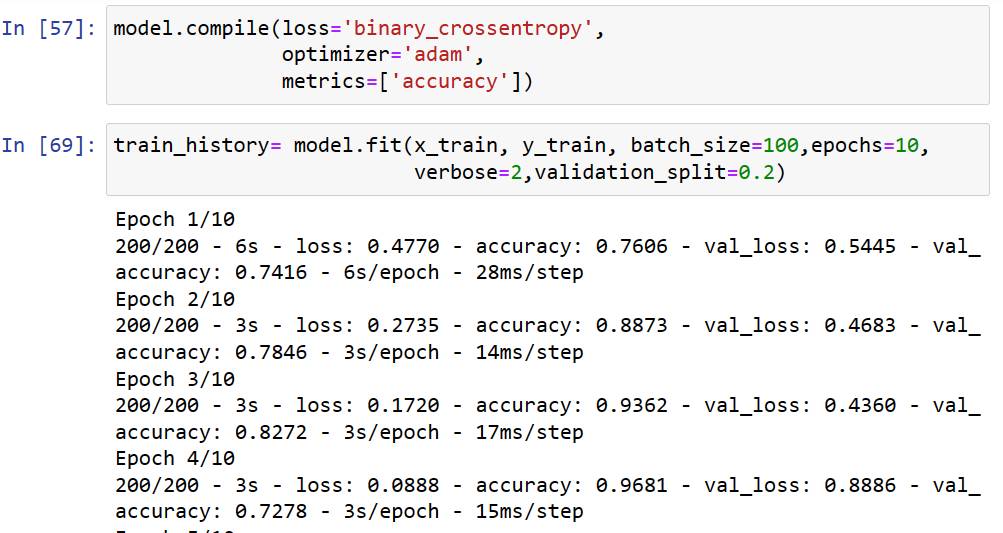
使用超小型MLP進行訓練,最小批次設定為100,epoch迴圈數設定為10次,驗證組比例設定為20%。訓練10次後,訓練組準確率為99.12%,驗證組準確率為72.96%。實際在跑時,是要參考驗證組準確率的。效果算是不好的,因為使用的模型太簡單。
STEP9.評估效能,使用Test Dataset評估
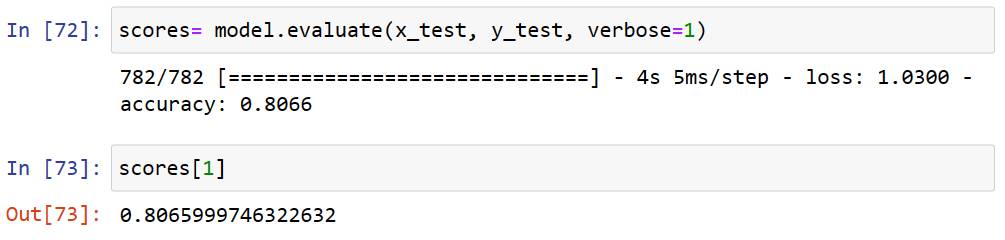
拿測試組資料來做二次驗證,發覺準確率為80.66%。
STEP10.建立預測模型
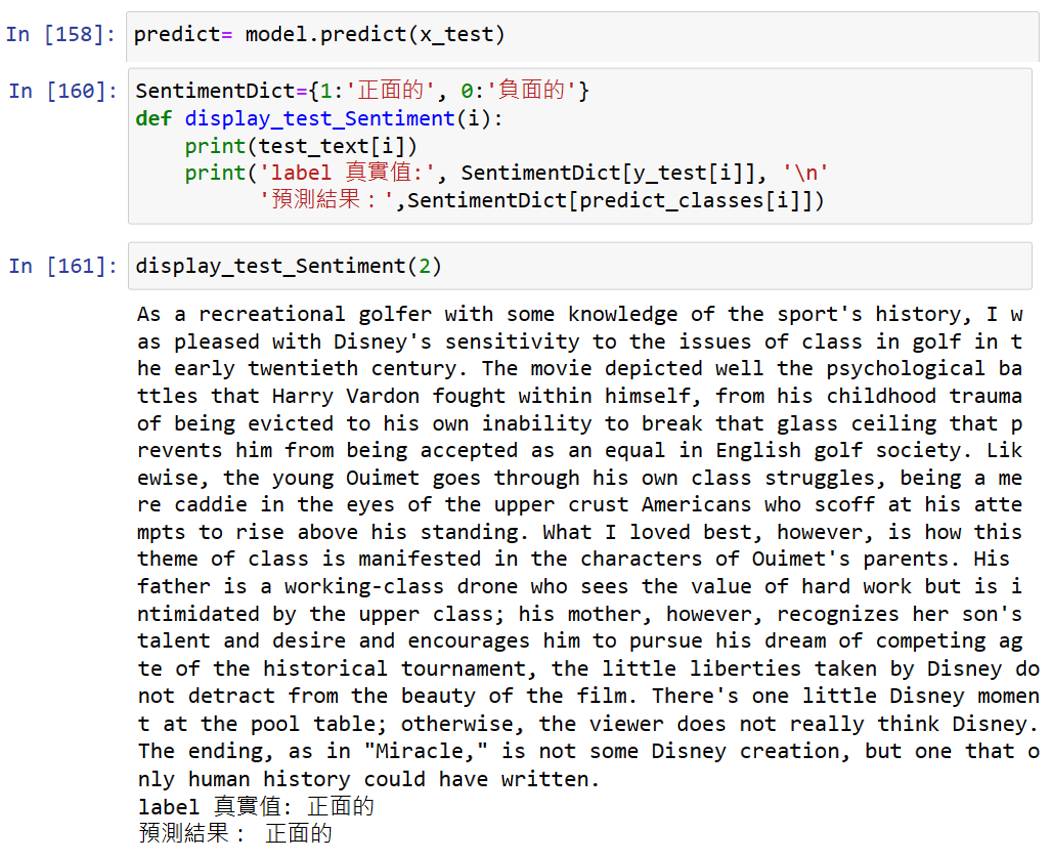
建立預測模型,這樣未來就可以餵自己的資料來做預測啦! 建立好後試跑看看每一組的預測值,因為前25,000組是正評,所以算出來接近1是正常的,表示模型正確。把預測數值轉換為文字顯示,比較容易理解數值意義。建立轉換測試結果函數,可以用來檢查每個測試檔的真實值跟預測值差異。
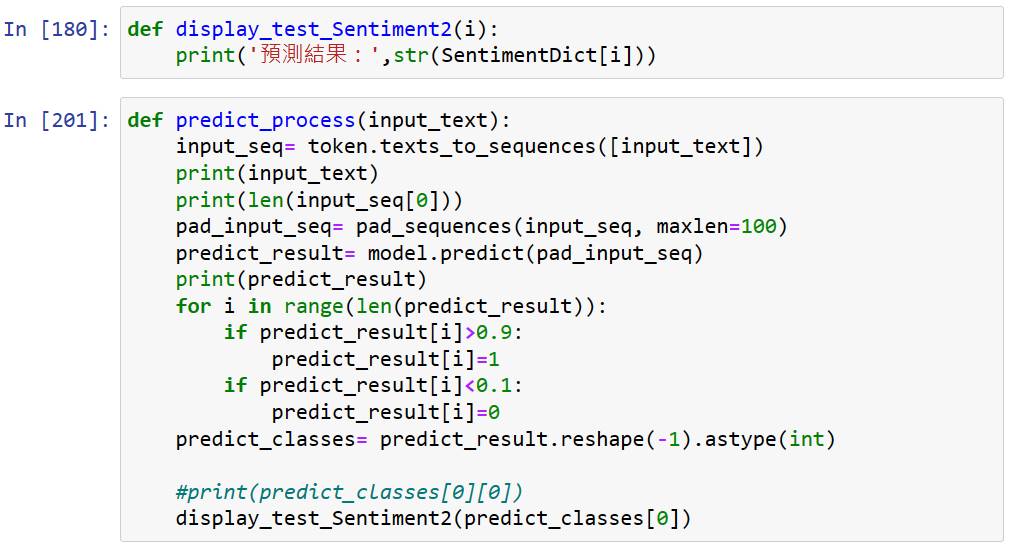
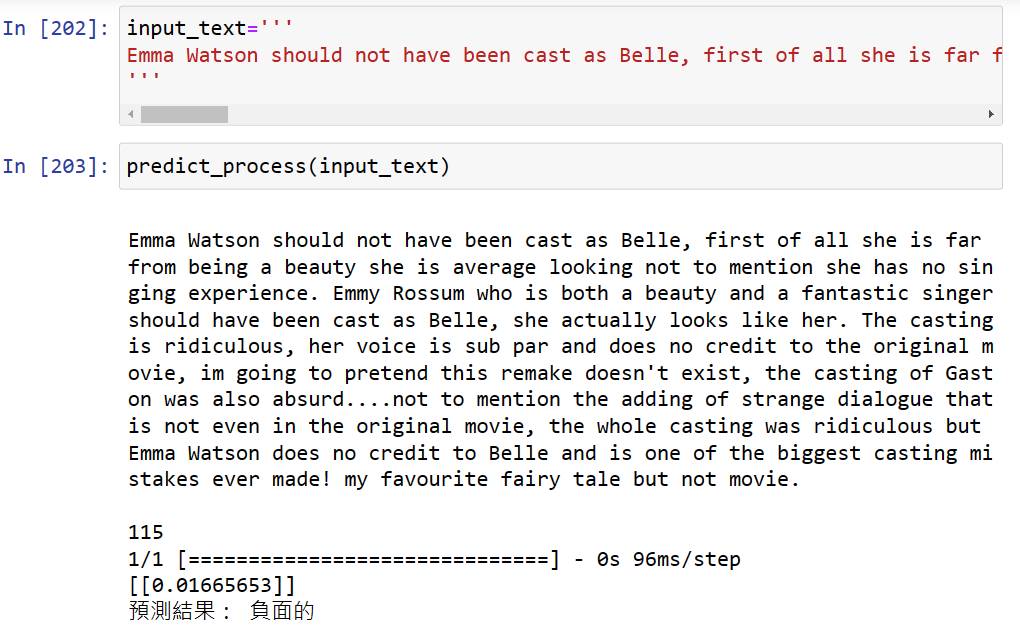
建立自訂值的預測函數。從這裡就可以直接放入文字到input_text,就會自動輸出預測結果。
在IMDb網站上隨便複製一段影評,確定他是正評或是負評,像這段它就是負評。也可以依照機率可能機率來區分幾星,就可以知道這段文字評分約是幾星了!
結語
這邊說明了影評的情緒分析。總體而言,使用英文的訓練相對簡單,在詞性抓取上比較沒問題,若是中文時,需要再安裝其他packages,才能夠正確使用。另外,因為使用的模型相對比較小,預測精準度就會相對性變低,可以再挑選比較好的模型來進行訓練,評分會更準確。
提供ChatGPT AI應用指南學習 – ChatGPT 與 Python 社群網路輿情分析實戰班
ChatGPT 社群分析相關新聞
AI應用技術擴散飛快,你知道目前市場上已經有哪些應用實務?
– 最新突破!OpenAI推ChatGPT官方外掛:能連網更新、訂餐廳>>>瞭解更多 〔註1〕
– 玉山銀行開始運用ChatGPT協助KYC開戶調查,未來Chatbot客服也要用?>>>瞭解更多 〔註2〕

{kind=link}